昨天我在阿里云上的网站突然在15:10分时打不开了,此时想通过ssh连接服务器也连接不上。这样的情况近期已经第三次出现了,每次都是强制重启服务器后解决,但这并没有找出问题本质,没有从根本上解决问题,于是这次我在阿里云后台发起了工单,请求协助排查问题。后来阿里云人的技术人员确实也给了我反馈:
您好,这边查看您的实例磁盘BPS超过您的云盘规格性能的BPS,系统无法响应您的正常操作。
然后他还给了我两个建议:
1. 建议您考虑重启服务器恢复,请您自行评估重启对您业务的影响。
2. 建议您在您的实例系统中安装atop工具记录日志,后续通过日志排查CPU、内存、磁盘读写、带宽(监测网络使用率要安装网络监控模块netato)使用较高的进程。
使用atop监控工具:https://help.aliyun.com/zh/ecs/how-to-use-the-linux-system-atop-monitoring-tools
提示:为避免atop长时间运行占用太多磁盘空间,建议将默认的日志保留时间28天修改为7天。
此外,他还建议如果您的磁盘现在读写很高,可以参考文档查看Linux系统I/O负载:https://help.aliyun.com/zh/ecs/support/query-and-case-analysis-linux-io-load
我对"BPS超标"(每秒字节数)比较疑惑,于是自行做了搜索学习,发现有人遇到同样的问题,也给出了解决方法。于是我也同样作了检查:
根据时间轴检查系统日志:
cat /var/log/messages
发现在15:09分的时候确实有过异常,看下图:
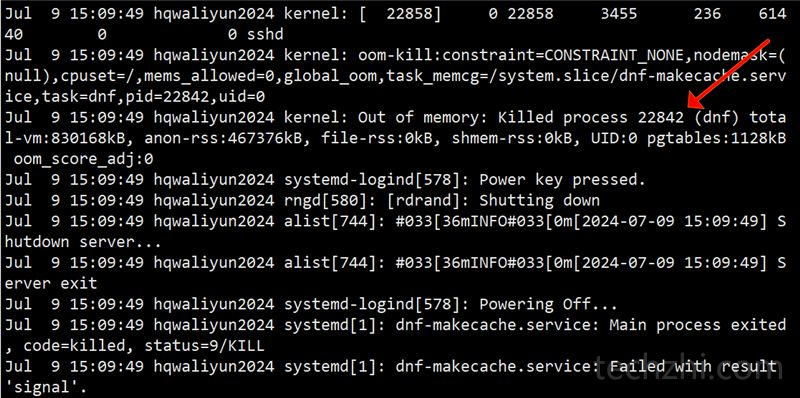
15:09分的时候确实有状况,注意到这一句:
Jul 9 15:09:49 hqwaliyun2024 kernel: Out of memory: Killed process 22842 (dnf) total-vm:830168kB, anon-rss:467376kB, file-rss:0kB, shmem-rss:0kB,
杀死了ID为 22842 的 dnf 进程(后面的total-vm、anon-rss和file-rss还不太清楚,需进一步读取)
猜测是dnf后台更新缓存导致磁盘IO高导致,并且看到这里应该更新导致内存不足,然后后面系统陆续杀死了各种进程。
解决方案,卸载dnf或者关闭make-cache的动作:
systemctl stop dnf-makecache.timer
systemctl disable dnf-makecache.timer
问题暂时是解决了,后续情况需进一步观察。